Oops, I Wrote a C++ Compiler
TL;DR I wrote a .NET library that can compile C/C++ code into a byte code that it can also interpret. It is used in my app iCircuit to simulate Arduinos. You can use it yourself with the nuget package CLanguage.
Arduino Support for iCircuit
The most requested feature for iCircuit, for years, has been to support Arduino components. I agreed with all my users that it would be an amazing feature, but it was also a pretty big request that I wasn’t sure I could complete.
I could easily add a component that looked like an Arduino - had all the right pins, maybe even blinked an LED. However, what people really wanted was a programmable Arduino integrated into the circuit simulator.
Arduinos are programmed in C++ with a small base library known as “Wiring”. Therefore, in order to simulate an Arduino, I needed a C/C++ compiler and I needed to re-implement Wiring. Oh, and that compiler needs to run on iOS, integrate into my circuit simulation, handle bad code such as infinite loops and bad pointers, work within the sandbox (which means interpretation instead of real execution), and it has to run on 4 platforms (iOS, Mac, Android, Windows).
Like I said, it was a big request! As tough as all that sounds, I still personally wanted the feature and decided to find a way to make it happen. Way back in 2010, I started work.
I first looked around for small C++ compilers and interpreters that I could get to work on iOS, Android, and Windows (iCircuit runs everywhere). Sadly, the research was grim as no compiler met all my requirements. Some would be nice and small but only emit X86 code meaning I would have to write an X86 simulator. Others were so big and had so many dependencies that I just gave up trying to get it to compile for iOS.
Fortunately in 2010, I was full of hubris and I figured now was the time in my life to write a C++ compiler. Oh how foolish…
The Halcyon Days of 2010
Compilers and Interpreters are, in principle, very simple programs. I’d written a bunch of interpreters at this point in my career and even wrote a couple simple compilers for very small languages. I knew that C++ was a complex language, at least syntactically (with all its type declarations) but that its semantics - its model of computation - was rather basic. I considered myself a good C++ programmer and thought I knew the language inside and out. How hard could it be?
Like I said, hubris.
And so I embarked on writing my C++ compiler in C# (the language iCircuit is written in). I started by writing a C compiler because C++ is a monster of a language. Most Arduino programs only use C features (I thought), so it seemed like a reasonable starting point.
Writing the Parser
C is nice because you can actually parse it using a grammar definition - a file that states the syntax of the language. Grammars are great because you can use a code generator to automatically create a parser for your language from this definition. This means you can focus on the semantics of the language and let the parser generator deal with the syntax.
Back in 1985 someone posted a YACC grammar definition for C which served as my starting point. I then used the jay parser generator (the same tools used to generate the mono C# parser) as my parser generator. This tool takes the grammar definition and spits out nasty C# code to parse files. The code is nasty because it’s fast and eschews standard coding conventions for performance. I love it.
The process of creating the parser went very smoothly thanks to this. The real work involves creating C# syntax classes that mirror the grammar. These classes form the Abstract Syntax Tree (AST) of the compiler. You can see the results of this work by looking at my modified grammar.
I ended up writing a variety of syntax classes such as:
ForStatementthat captures the syntax offorloopsBinaryExpressionthat handles most math operators such as+and*Blockthat captures a sequence of statements
And this is the point where I realized C was a bit more complex than I liked to think. My syntax classes were filled with scary names like “abstract specifiers”, “type specifier”, “type qualifier”, “multi declarations”, and so on. I knew C declarations were nutty but, oh my, they’re a disaster.
I was scared, but combatted that fear by writing a bunch of unit tests. I figured, yes this problem is hard, but it’s just big - there was an end in sight. Maximum effort would be needed and would, hopefully, be rewarded.
And so I pressed on. I just kept writing sample code after sample code until I understood how my concept of the language related to this grammar. After some time, I was able to wrestle all these “specifiers” into more manageable objects.
Definitions and Types
The next step to writing a compiler is discovering definitions in code. Variable definitions, function definitions, type definitions, all that. C and C++ are a little wild because you can declare things multiple times but you can only define them once. While C++ is designed to be compiled using only a single pass over the AST, I ended up writing a multi-pass compiler with separate stages for declaration discovery, resolution, and emission.
Once I found declarations and definitions, I needed to build a type system. Thankfully, at first glance, C’s types are very basic. You have the machine types (ints and floats), structures, and, uh oh, pointers. The compiler would have to munge around all the code and assemble and unify all these types. I spent days and days just getting the integers right.
For example, we all know what this means:
int foo;
But what does
int long long short long foo;
mean? Unfortunately, that is valid code according to the grammar I’m using, but it’s obviously not valid C code. The compiler has to deal with this kind of craziness. Not even the integers are simple in C…
Emitting Executable Code
Now it’s time for the compiler to earn its keep and emit executable code. Most C compilers would emit X86 or ARM assembly. However, there was no point in doing that as I can’t natively execute code on iOS.
I decided to instead devise my own virtual machine and byte code that would be easy to interpret. I figured that if I controlled the compiler and the byte code then I could arrange things to make the interpreter simple and yet still expressive.
This was a bit of a gamble as it increased the number of decisions I had to make. However, most byte codes I looked into were very complex and I knew (I thought) I could keep my code small and simple.
I settled on a stack-based virtual machine that is very similar to how the Common Language Runtime (CLR) works. Every function had a stack and computations were performed by pushing and popping numbers to and from that stack. This is different from most real machines like X86 that are register-based not stack-based. Register-based machines scared me a bit because they reminded me of very hard to read chapters of very hard to read books. I knew how to implement them, but I lacked experience with them and went with the simpler design.
Now that I had a semi-specified byte code and virtual machine,
it was only a matter of translating my syntax tree into byte
code. If you ignore performance, this is a trivial step for the compiler.
You can see, for example, how if statements get compiled by looking at the
DoEmit method of IfStatement:
protected override void DoEmit (EmitContext ec)
{
var falseLabel = ec.DefineLabel ();
var endLabel = ec.DefineLabel ();
Condition.Emit (ec);
ec.EmitCastToBoolean (Condition.GetEvaluatedCType (ec));
ec.Emit (OpCode.BranchIfFalse, falseLabel);
TrueValue.Emit (ec);
ec.Emit (OpCode.Jump, endLabel);
ec.EmitLabel (falseLabel);
FalseValue.Emit (ec);
ec.EmitLabel (endLabel);
}
This code first emits the condition. It then emits a branch to one of two
blocks - either the main body (TrueValue) or the else body (FalseValue).
I stole this emit architecture from the mono compiler - always steal from the best.
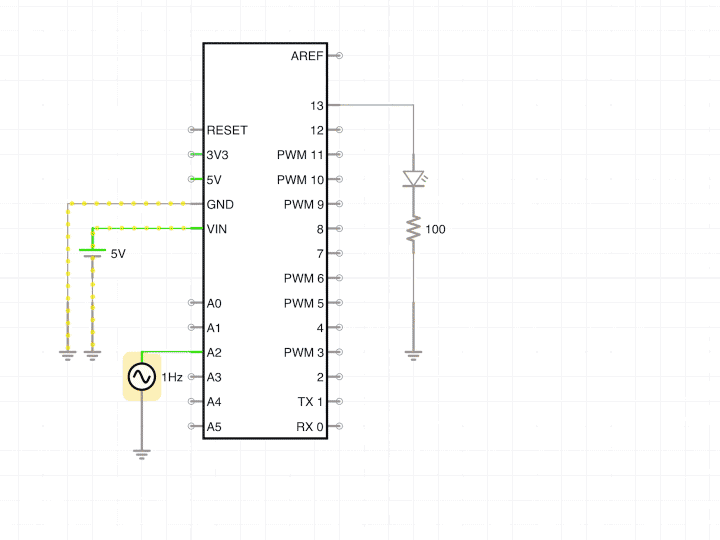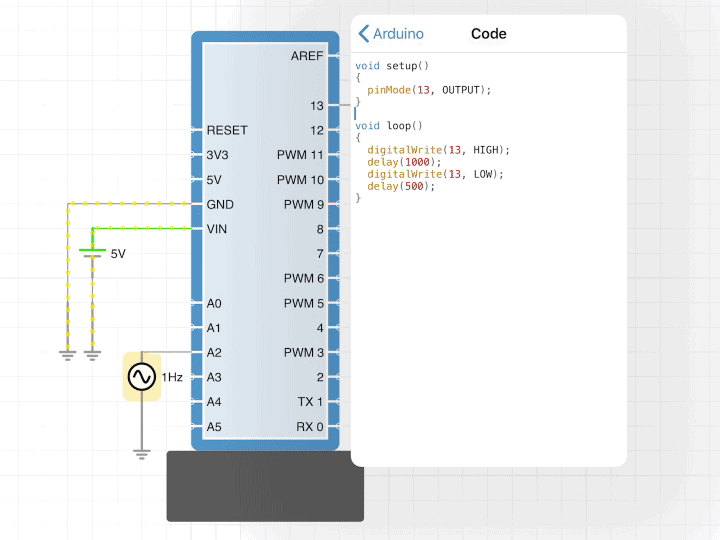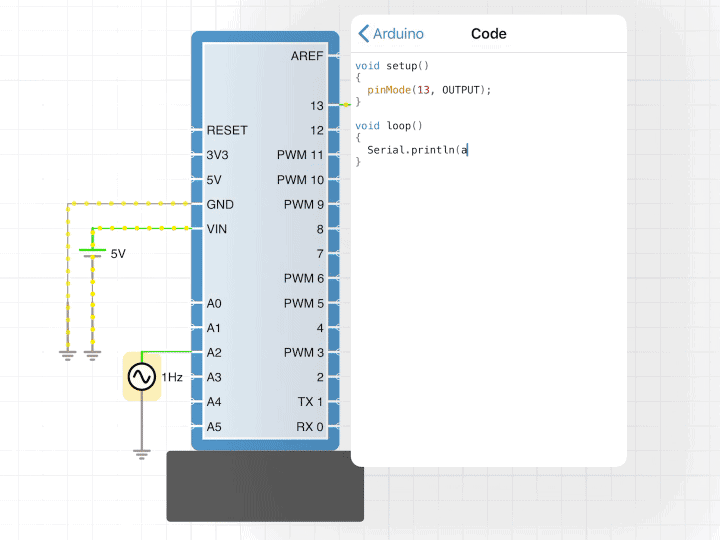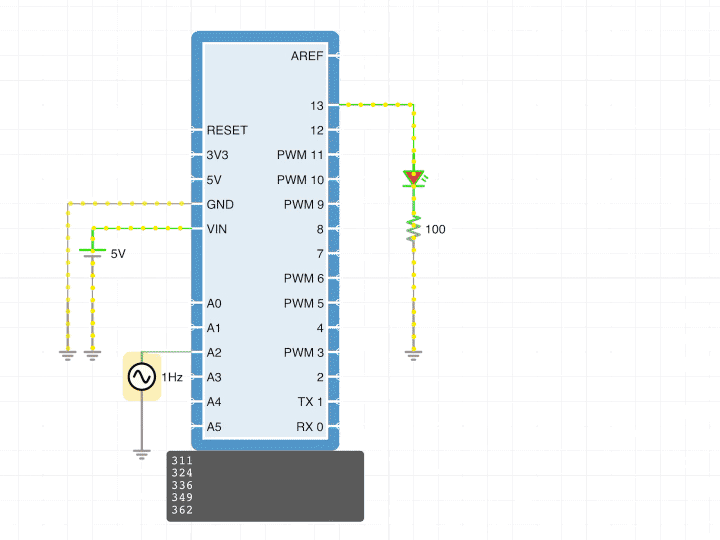
Most of those early decisions paid off well and after a few weeks of work I was able to compile and interpret the most basic of Arduino programs.
It was the hardest I ever had to work to get a stupid LED to blink.
Enough
But that victory was met by a cold realization of just how much more work was left to be done.
My compiler was working but it could only do math with 32 bit integers. My clever interpreter was stack based - which, turns out, is not at all compatible with C’s flat memory model. I had no idea how I would make real pointers work. I still didn’t have support for structs. And this was all just for the C compiler - I still needed to add C++ features!
And so, sadly, I gave up. It’s never easy to admit, but sometimes problems are just too big for you.
2018
Eight years is a long time and it’s funny how memories distort. I was working on the feature set for iCircuit 2 and Arduino was the first item on that list. I knew I had a compiler capable of making an LED blink, and my memory told me the compiler was nearly done it just needed a bit more work. This time I reopened the code reluctantly, without hubris, mostly curious to see what I would find.
I was pleasantly surprised to see how much ground I had covered so long ago. I also realized that my memory betrayed me - the compiler had some serious defects (no support for strings as a prime example) and that it was going to be a lot of work to finish it. I remembered why I stopped 8 years ago.
However, after some thought, I decided that it was still useful. It allowed you to use the majority of the features of the Arduino and provided all the basics you needed to write fun programs. I decided to release that compiler in iCircuit 1.9 to finally provide the most requested feature of the app.
I was nervous, but very pleased to see that the Arduino component quickly became one of the most-used components in the app and users seemed to love it.
Back to Work
The enthusiasm for the Arduino component made me want to improve it and I set about fixing its most glaring defects.
Numbers
All math in the 2010 compiler was done with 32-bit integers. While the compiler was well aware of different data types, my virtual machine was not. It needed to be fixed to support other integer sizes, unsigned math, and floating-point numbers.
This also meant implementing conversions (casts) between all the types would need to be supported. It’s unglamorous and terrifyingly boring code to write but it needed to be done.
I have since concluded that 95% of a C compiler’s job is to convert between data types.
Pointers and Arrays
Pointers and array support exposed the most glaring defect in my virtual machine - the use of separate memory spaces.
C++ naturally has several memory spaces: global data, heap data, local variables, and function arguments. My interpreter dutifully kept those spaces separate. However, this meant that I had to track several “types” of pointers - depending on what memory regions they pointed into. This greatly increased the complexity of the compiler whenever it had to deal with pointers (which was often).
Unfortunately, C++ programmers assume a unified memory space - you can create pointers to any of these memory spaces and they all work they same way. Worse, C supports pointer arithmetic and people can do terrible things by casting pointers to integers. These tricks were not supported at all by my virtual machine.
I decided to stop fighting and to unify my memory model. Before, the function call stack was separate from the heap and kept its own private memory spaces for arguments and local variables. I had to integrate that call stack onto the main memory stack by using a “frame pointer” register that remembers where in memory each function’s value (computation) stack begins. I also had to emit relative addresses for local variables and arguments that got offset by this frame pointer. Such a mess!
But the pain was worth it as my compiler and virtual machine could now handle pointers and arrays of any variety and acted as the user expects. This would also enable me to simulate hardware registers if I should ever need to.
And thanks to C#, all this pointer work is safe. The entire heap for the program is stored in a C# array. When a pointer is de-referenced, that array is safely accessed and I have no fear of breaking the simulation just because some code is incorrect.
Classes
While most Arduino programs take advantage of C features, Arduino libraries tend to take advantage of C++ features; namely, classes.
Everyone’s favorite Arduino line:
Serial.println("Hello world!");
does not work on the 2010 compiler. It requires these C++ features:
- Class definitions
- Member method calls (with
thispointers) - Function overloading
Each of these posed their own set of hurdles and, in the end, forced me to rethink my ABI (Application Binary Interface - how arguments are passed to functions).
I was so relieved when I got that line working because, as it turns out, people love printing to the console and I absolutely had to have that feature.
I’m very excited to say that Version 1.9.1 of iCircuit shipped with these improvements.
The Future
While I love my compiler, I am still overwhelmed by the features it’s missing. Still up for grabs are:
#defines with arguments- Templates
- Constructors and destructors
- Inheritance and virtual methods
- Editor integration (better errors, code completion)
and I’m sure a million other things could be listed if I dared.
I decided to open source the compiler and interpreter to hopefully get a little help from bored compiler authors out there. Perhaps too you might have a need for a little embedded C/C++ in your apps (not sure why though haha).
I hope you’ll check out the CLanguage package and contribute on github if you have any interest.
But the truth is, I’m just going to keep listening to users and improving the parts I can. I am not trying to recreate GCC or LLVM. Instead, I’m trying to provide a fun and engaging environment for people to experiment with coding. While it’s just a virtual LED blinking in iCircuit, it’s still gives me a gleeful smile. I hope it gives you one too. :-)